
 An individual’s health is an incredibly personal subject, and going to the doctor can be an intimidating and stressful experience. This is especially true for people that are part of groups that the medical system has historically failed. These structural issues in the healthcare system have permeated the algorithms that are increasingly being used in the diagnosis and treatment of patients. CCC organized a panel, “Health Equity: How Can Algorithms and Data Mitigate, Not Exacerbate, Harms?” that addressed these issues. The panelists were Dr. Amaka Eneanya (Fresenius Medical Care), Dr. Mona Singh (Princeton University), Dr. Melanie Moses (University of New Mexico), and Dr. Katie Siek (Indiana University).
An individual’s health is an incredibly personal subject, and going to the doctor can be an intimidating and stressful experience. This is especially true for people that are part of groups that the medical system has historically failed. These structural issues in the healthcare system have permeated the algorithms that are increasingly being used in the diagnosis and treatment of patients. CCC organized a panel, “Health Equity: How Can Algorithms and Data Mitigate, Not Exacerbate, Harms?” that addressed these issues. The panelists were Dr. Amaka Eneanya (Fresenius Medical Care), Dr. Mona Singh (Princeton University), Dr. Melanie Moses (University of New Mexico), and Dr. Katie Siek (Indiana University).
Dr. Eneanya began the panel by discussing how an equation systematically underestimated kidney disease in Black Americans for decades. She explained that in the US, all patients that have kidney disease are entered into a registry. The prevalence of the disease has increased overall in recent decades, and for Black individuals it tends to be even more prevalent and severe.
Dr. Eneanya outlined these racial/ethnic disparities in chronic kidney disease (CKD) risk factors and outcomes (Eneanya ND et al. Nature Rev Neph. 2021, United States Renal Data System.):
- The prevalence of diabetes is highest among Black individuals compared to other racial groups
- Black and Hispanic individuals are diagnosed at younger ages compared to White individuals
- Black individuals have significantly higher rates of hypertension compared to White individuals
- Hypertension control is less among Black and Hispanic individuals compared to White individuals
- Black individuals are less likely to receive nephrology care prior to starting dialysis compared to other racial groups
- Risk of developing kidney failure that requires dialysis or kidney transplantation
- 4-fold higher in Black versus White individuals
- 1.3-fold higher in Hispanic versus White individuals
- Black individuals are less likely to receive kidney transplantation compared to other racial groups
Structural racism adds to poor health outcomes from kidney-related diseases, Dr. Eneanya elaborated (Eneanya ND et al. Nature Rev Neph. 2021.):
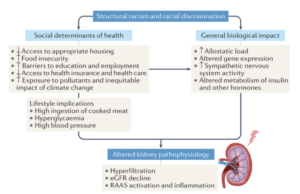
What lifestyle habits you are able to afford – such as what you eat, and biological impacts like the stress of racism and discrimination all lead to metabolic changes in the body, which can lead to decreased kidney function.
Dr. Eneanya pivoted to an example of how an algorithm currently in use by clinicians has real-world consequences. The eGFR equation is an algorithm used to determine how strong a patient’s kidney function is. A higher eGFR represents better kidney function. A patient’s eGFR level determines if they are eligible for certain treatments, and, perhaps most crucially, a kidney transplant. However, the algorithm shows that a Black and non-Black person that are the same age, gender, and have the same creatinine measure (a blood test that measures kidney function), have different eGFR levels. The algorithm calculates that a Black person has a higher eGFR, supposedly superior kidney function, than the Non-Black person. This limits the treatment they are eligible for, and means they need to be sicker to receive the help they should be entitled to.
Dr. Eneanya explained the history of the algorithm that reveals why it calculates in this misdirected manner: a 1999 study attributed higher serum creatinine to Black individuals because of the incorrect assumption that they had higher muscle mass. The study developed the first eGFR equation used in the United States and incorporated a “Black race” multiplication factor that causes higher eGFR among Black individuals. The use of the eGFR is problematic because clinicians are left to judge someone’s race based on appearance or medical records (that may have race listed as a leftover assumption from a previous clinician). There also isn’t a distinction for mixed race individuals, or a method to classify them.
Dr. Eneanya was an author on an article that changed how eGFR is calculated in healthcare by advocating for an equation that does not take race into the estimation (Inker LA, Eneanya ND, et al. NEJM 2021, Delgado C, et al. JASN 2021). Dr. Eneanya and her colleagues returned to the original 1999 study and removed race from the equation and refitted it with other inputs. Today, ⅓ of hospitals and clinics in the US are using the new equation, and the United Network for Organ Sharing (UNOS) notably restricted all transplant centers from using the race-based equation in June 2022. They took it one step further in January 2023 and declared that all US transplant centers are required to review all Black patients on the kidney transplant waitlist and modify their waitlist time if it was impacted by the race-based eGFR equation. Dr. Eneanya specified that while UNOS is part of the federal government, the government was not directly involved with the decision to ban the use of the race-based equation.
Other than universal adoption of the new eGFR equation, Dr. Eneanya had a few more future approaches that she sees as key to equitable access to kidney disease treatment:
- Develop policies and processes to improve access to chronic kidney disease preventative care
- Develop policies to increase access to kidney transplantation
- Investigate environmental effects (e.g., stress, discrimination) on kidney function and disease progression
- Transparency in discussing kidney function determination with patients (including limitations of eGFR equations)
Dr. Eneanya elaborated that teasing out stereotypes about Black race boils down to eliminating fallacies and fake news that have no scientific basis. For instance, medical school curriculums are changing to show there is no anthropological basis that there is more muscle mass in one race over another. The media has done a good job of sharing this busted myth as well, and Dr. Eneanya even consulted on a Grey’s Anatomy episode that highlighted the devastating impacts of the eGFR equation for Black patients in need of a kidney transplant.
Dr. Singh continued the conversation about health disparities by explaining that in the US, Black individuals have higher cancer mortality rates as compared to a White individuals. This fact exemplifies that there are many challenges that medical professionals and computing researchers need to face, there are also many opportunities to develop methods that don’t widen existing disparities.
Dr. Singh first explained the biology of cancer: “Cancer is a disease where our own cells acquire mutations that allow them to grow uncontrollably. So If we want to understand the molecular underpinnings of cancer in any ONE individual, we can look at the genomes of his or her cancer cells and his or her non-cancerous cells, and sequence. Once we have sequenced normal and cancer cells, we can compare the genomes, and uncover which mutations we acquired in cancer cells, and this may give us a hint as to what alterations may be the ones that are relevant for that individual’s cancer. This is precisely what has been done in the past 15 or so years, where the tumors of tens of thousands of individuals have been sequenced, and mutations within them identified.”
Pretty much everyone knows someone who has been diagnosed with cancer, and there is no universal cure. However, Dr. Singh next discussed the promise of precision oncology, where a scientist sequences a patient’s tumor, identifies their DNA mutations and performs computational analysis to determine which alterations can be targeted. Immunotherapy is an approach to harness someone’s own immune system to target their tumors. A promising up and coming immunotherapy is to design vaccines that are personalized to each individual and these vaccines evoke an immune response to their tumors.
Dr. Singh explains the way this works is that each of our immune systems have 6 different copies of the classical major histocompatibility complex (MHC) class I genes. There are over 13,000 different MHC variants of these genes, so each person has a different set of MHC genes. Some mutations within cancer cells result in “foreign” proteins and some of these can be bound by an individual’s MHCs. These complexes of MHC bound with a fragment of cancer-derived protein are recognized by immune cells and can activate an immune response. This is highly personalized as each individual’s tumor can have different mutations and each individual has different MHCs. Scientists are using machine learning to predict what MHC variants bind which peptides, which will hopefully advance the efficacy of immunotherapy and ultimately lead to the design of personalized neoantigen vaccines.
The variety of MHC genes vary vastly across the globe, Dr. Singh elaborates. Most MHC alleles have no binding data associated with them, and the ones that do have data about their binding are biased in favor of some racial groups. It is important when testing a data set to not just focus on overall performance, but also to consider subpopulations of data so that everyone has equal access to the potential benefits of this research.
The training set must be analyzed for bias prior to being applied. Furthermore, methods to estimate performance on unseen data can reveal bias in the data it was trained on. Collecting data in an unbiased manner is essential to limit the opportunity for bias later in the usage of the algorithm. Areas for future work on this topic are focusing on alternate training procedures, and algorithmic strategies for targeted data collection. Overall, it is crucial to prioritize the development of fair precision medicine approaches so that therapies and research downstream are equitable.
Dr. Moses spoke next and she contextualized how the eGFR and MHC-peptide binding algorithms fit into a larger ecosystem of how medical algorithms affect social outcomes. She explains that scientists use algorithms and AI to predict outcomes we care about from proxies that can be easily measured, and those proxies can be inaccurate. To make medical algorithms even more complicated, they are constantly interacting with each other in unpredictable ways so the full extent of algorithms on the diagnosis of a patient is typically unclear. Therefore, it is crucial to use algorithms with caution, especially because when the algorithms fail they can be most harmful to the most vulnerable.
Figuring out who an algorithm impacts and why is an important part of medical equity. Dr. Moses takes a step back and defines equity. The common graphic used to differentiate equity from equality, with individuals with 3 different heights struggling to see a baseball game and different ways to support them, is flawed even in the 3rd image that removes the barrier because it suggests that there is something inherent to the person as to why they need the support rather than social reasons which may have caused the inequity in the first place.
Dr. Moses showed an alternative graphic to define what equity looks like in a society with systemic injustices (Copyright 2020 by Nicolás E. Barceló and Sonya Shadravan (Artist: Aria Ghalili)):

This graphic reveals that not everyone can benefit just from the barrier being removed, but there are deep rooted problems that need to be dealt with in order to achieve equity.
Computing scientists should always keep this important context in mind, Dr. Moses argues. It is oftentimes difficult to identify the assumptions that were present in the creation of algorithms, even with the most straightforward algorithms. It is also easy to use a statistical correlation to predict an outcome and presume that correlation equals causation, but that is a fallacy.
Dr. Moses continues by giving concrete examples of inequitable algorithms that are in use in society today in other domains. For instance, algorithms in the criminal justice system that replace monetary bail for pre-trial detention. The intent is for the process to be a data driven, unbiased method to detain those who are a danger or high-risk to fail to appear for trial. However, the algorithms have many shortcomings in both the ability of the algorithm to make fair and accurate predictions and the biases of the system the algorithm is part of, including biased inputs and biased interpretations of outputs. Another example of how racial bias is perpetuated in the criminal justice system by algorithms is facial recognition software. While facial recognition has been shown to be least accurate in identifying darker-skinned female faces, it is Black male faces that have most often been misidentified by these algorithms leading to false arrests. This demonstrates how bias that most affects one group (Black women) in terms of accurate classification, can have the greatest impact on another group (Black men) because of biases in the criminal justice system
Algorithms can exacerbate human bias, and can also be dismissed if they aren’t reinforcing the judgment you would have made without consulting the algorithm. This is true in biased algorithms in medicine, too. For example, pulse oximeters are less accurate at detecting oxygen levels in darker skin, which can result in the underdiagnosis of respiratory illnesses like severe COVID. Using the amount of money spent on healthcare as a proxy for how healthy someone is is another inequitable measure. The examples Dr. Eneanya and Dr. Singh described, the eGFR kidney discounted kidney impairment in African Americans, and genomic datasets overrepresenting European ancestry, are other prominent examples of biased algorithms in medicine that have dangerous downstream consequences for the people impacted. The eGFR equation was used to identify prisoners sick enough to be released from prison during COVID, which resulted in an African American man being denied release because his kidney function was overestimated.
Feedback can improve algorithms, or exacerbate their harms. Algorithms are not a one-way street, as they aim to predict behavior from data and one year’s prediction affects the next year’s data. Algorithms should aim to decrease biases over time; for example, bail hearings should help defendants show up for trial rather than predict failures; policing should aim to reduce both crime and false arrests. Algorithms used across domains should never be set in stone because there will be feedback between people, algorithms, and social context.
Dr. Moses proposed additional paths forward as well: remove bias from datasets, question assumptions, reverse (not reinforce) systemic bias, evaluate with a diversity of perspectives, demand transparent & explainable algorithms, and use gradual, adaptive deployments. The common perception is that algorithms somehow remove bias, but in reality they often codify bias and we need to be wary of algorithms and their outcomes.
The final portion of the panel was a Q&A. Moderator Dr. Siek kicked off the session by asking, “how can algorithms and data not exacerbate harms?”
- Dr. Eneanya: If a researcher is stopping with race when looking for differentiators in an algorithm, that is lazy and scientifically invalid. Genetically, humans look more similar between races than within. It is more important to think about biological characteristics that actually impact a human system like kidneys. For example, when testing the pulse oximeter, researchers should have consulted with a dermatologist to test and validate pulse oximeters based on different skin tones – rather than using one type of device for people with different skin tones.
- Dr. Moses: We should use that same approach to validating algorithms after they have been put in use. Recognizing race as a social construct allows noticing race blind studies have impact. It is important to look for distinction between groups to identify potential disparities that the algorithm is reinforcing. Have to evaluate if the algorithm is minimizing problems, or making it better?
- Dr. Singh: Race should never be used as an input, but it can be used to evaluate outputs for bias. If we didn’t think about race we wouldn’t even be able to say there are health disparities. Collecting genomic data and categorizing by ancestry is also a flawed methodology. We have to make sure to evaluate if methods work well across populations.
- Dr. Eneanya: When we are diversifying a study population, we need to move away from just bringing in groups of white or black people. We need to look at more differences within these groups such as factors like social status, gender, sexuality, etc. We need to look at the whole picture and not just diversity datasets based on race.
- Dr. Moses: Algorithms are exactly the types of tools that should help us do that, there are a lot of potential computing strategies that can help.
- Dr. Singh: I agree that algorithms play a huge role here, so how do we prioritize data collection? We need to think about how we do that very carefully.
An audience member then asked, “Given the major rush to develop algorithms based on current datasets with biases, are there ways to counteract bias in the algorithm beyond getting rid of biases in the dataset?”
- Dr. Singh: It is hard to overcome bias in a data set; it is an active area of research. It is easy to over or under sample data. There are different ways to train ML models where the overall goal (typically a function you are trying to minimize, usually using the whole data set) is what optimization should look like.
- Dr. Eneanya: A lot of medical algorithms are viewed as needing to include race to be more precise.. However, people need to critically examine why race is being introduced in the first place? Removing race as a variable may not change the performance of the algorithm as much as you might think. Does it mean anything (clinically) when the results change by only a tiny bit after removing a variable such as race?
- Dr. Singh: It especially doesn’t mean anything when your training set and the set you use it on are very different.
Dr. Siek prompted the panelists with another question, “If we could do this all over again, what would we do differently?”
- Dr. Eneanya: Stopping with race when evaluating reasons for differences in health outcomes shouldn’t have happened. For instance with creatinine levels, we should think about what else can impact creatinine? We need better data sets, which requires building trust in communities. This can look like improving the diversity of trial populations, evaluating what your study staff looks like, etc. National Institute of Health grants are increasingly requiring community-based partners and health equity specialists as part of the research team. We need to change the old sets, but also need to build better sets in the future. We can only do so much with trying to re-configure what is out there.
- Dr. Moses: Beyond what could we do if we restarted, I like to think of algorithms as mirrors of society. They are trained by everyone on the internet. Using that as an input to the next level of algorithm, we can determine where the biases are, why they are there, and what the future impact is. We need to ask how to use these quantitative tools to figure out how to fix these situations rather than exacerbating them.
- Dr. Singh: A lot of genomes that have been collected don’t represent the population at large. We need to start with involvement from diverse sets of people.
The final audience question was: “Until we get to a point where we have a complete genomic picture of all humans, there will be enthusiasm to use ML and algorithms. What are real things at the peer review level that we can do now so we don’t have to fix them in 30 years?”
- Dr. Eneanya: Perfect is the enemy of good. We have to do the best we can. We can identify biases, then do the best we can moving forward. Barriers exist that have nothing to do with clinical algorithms. Just fixing the eGFR algorithm by getting rid of race won’t solve kidney disease disparities. A lot of work needs to be done on multivariable aspects of repression.
- Dr. Moses: The work you [Dr. Eneanya] have done to re-engineer the algorithm for all is exactly how to move forward. We need to be fixing the system. Also using the fact that it had to be fixed; it was easy to see the bias written into the equation. The kidney equation serves as a mirror for a society that allowed race to be encoded in a way that disadvantaged African Americans for decades. The bias in that equation was explicit and deliberate. It will be much harder to identify bias in more complex algorithms in the future.
Stay tuned for another AAAS 2023 CCC-sponsored panel recap!






{kind=link}