
The final CCC panel of AAAS 2023, “Maintaining a Rich Breadth for Artificial Intelligence”, was held on Sunday, March 5th, the last day of the conference. This panel was composed of David Danks (University of California – San Diego), Bo Li (University of Illinois – Urbana-Champaign), and Melanie Mitchell (Santa Fe Institute) and was moderated by Maria Gini (University of Minnesota).
Dr. Bo Li began the panel by discussing the importance of conducting trustworthy machine learning (ML), and the ways in which we can ensure ML is safe, equitable, and inclusive. Machine learning is ubiquitous, Li said, and today is used in a significant number of everyday activities, such as navigating to work, sending a “quick reply” via email, or even opening your phone using facial recognition. However, many of these technologies which rely on machine learning are susceptible to attacks. These technologies are also not infallible, and are known to make mistakes, such as facial recognition leading to false arrests.
Dr. Li then pointed to an article in PCMag, which predicted that the year 2023 will be a security nightmare due to increasing ransomware attacks and adversarial artificial intelligence programs. Fortunately, there has been a shift recently towards recognizing the risk of artificial intelligence programs. The release by the White House Office of Science and Technology Policy (OSTP) of the Blueprint for an AI Bill of Rights and the petition to halt further AI developments, which has been signed by many leaders in industry, including Steve Wozniak and Elon Musk, have shed light on the risks of rapid and unregulated AI development. The OSTP’s Blueprint for an AI Bill of Rights outlines the need for robust AI systems which are safe and effective and for algorithmic discrimination protections to ensure AI systems remain fair and equitable for all.
Dr. Li then dove deeper into a variety of adversarial attacks that are being used to thwart artificial intelligence systems. Li pointed to her own research into physical attacks, specifically in the case of image recognition of self-driving cars. In a paper co-authored by Dr. Li, she and her colleagues demonstrated the ease with which they could confuse a perception system into misidentifying stop signs using a variety of physical attacks, as shown in the image below.

arXiv:1707.08945 [cs.CR]
Dr. Li also pointed to attacks on MRI image recognition software, which can mislead the software to incorrectly segment MRI images, and misdiagnose tumors, as shown in the image below.
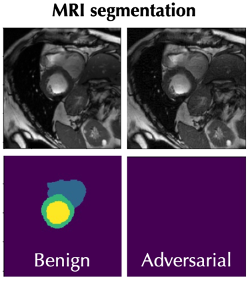
Improving the security and trustworthiness for AI, according to Dr. Li, is critical. This can be seen clearly in AI applications that rely upon time series data, such as the ability of facial recognition systems to identify a person’s face as they age. An issue that often arises when training a traditional machine learning model is the assumption of stationary data. A stationary dataset assumes that the mean and variance of a dataset are constant over time, as well as the covariance between two data points (eg. the covariance between data on day 9 and day 10 of a dataset is equal to the covariance between data on day 99 and day 100). While this may be true for a typical stationary dataset, this assumption often does not hold true when using real world data. The issue that arises is that when deploying a model trained on stationary data in a real world application, we are now making predictions about real world data which rely on assumptions that no longer hold true. This can result in inaccurate predictions or decisions made by the AI application, which can result in devastating consequences. While we can try to correct for the non-stationarity of testing data, it can be difficult to determine where and by what means to make these corrections.
The chasm between training data and testing data, Dr. Li says, creates what she calls a “Trustworthiness Gap”, where concerns of a lack of robustness, privacy, generalization, and fairness can arise. The goal here is to close the Trustworthiness Gap by shoring up the robustness of systems, allowing them to rebuff attacks, adapt accurately to new situations, and protect the privacy of individuals whose data is used by ML applications.
Dr. Melanie Mitchell then directed our attention past machine learning and beyond even traditional deep learning to discuss Generative AI. Dr. Mitchell gave examples of popular generative AI programs, such as ChatGPT, which can generate text responses to prompts, and DALL-E, which can respond to prompts with generated images. The media has postulated that generative AI programs such as these are fastly approaching a level of intelligence comparable to humans’. Mitchell, however, casts doubt on this pronouncement.
Dr. Mitchell mentioned a student of hers who trained a neural network to decide whether an image contained an animal. The model had a high degree of accuracy, but when Mitchell’s student did analysis to see how the program made its determinations, he realized that the program didn’t look at the part of the image containing an animal at all, but rather it focused on the background. Rather than learning to differentiate animal and non-animal parts of images, the model had actually taught itself that most images of animals have blurry backgrounds, and therefore it began to ignore the foreground of images entirely.
This example, Mitchell stated, clearly demonstrates a core issue with Artificial Intelligence: It is easy to get a program to learn, but it can be very difficult to make them learn what you would like them to. AI does not have the kind of common sense that even a toddler might have, so it is difficult to correct for the assumptions a computer might make that a human might never even conceive.
Most neural networks can also be easily fooled by placing clearly recognizable items in unexpected locations or orientations. Mitchell displayed an example created by a group of researchers at Auburn University. The image below displays a school bus in a variety of orientations. In the first orientation, the school bus is positioned as expected, and the neural network can easily identify the object with 100% certainty. However, when the school bus’ orientation is rotated into an unexpected position, the program fails at identifying the object every time, though it still makes identifications with high certainty.

Alcorn, Michael A., et al. “Strike (with) a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects.” arXiv preprint arXiv:1811.11553 (2018).
These kinds of mistakes that AI programs make can be very silly when you are working in the lab, but they can also have serious real world consequences, most notably self-driving cars crashing because they misidentify or fail to identify objects. Artificial Intelligence also struggles to determine when an object should or should not be identified. Dr. Mitchell showed two images (below), the first displaying a self-driving car’s camera identifying the images of bikers on a car as actual bikers, and the second showing a tesla slamming on the brakes every time it passes a billboard with a picture of a stop sign.
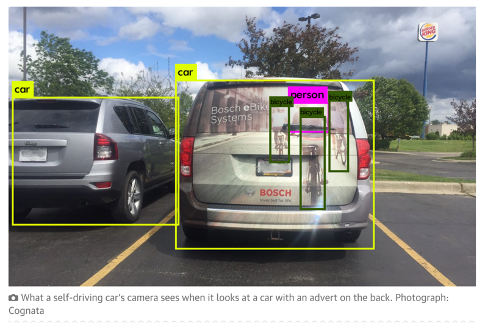
https://www.theguardian.com/technology/2017/aug/30/self-driving-cars-hackers-security
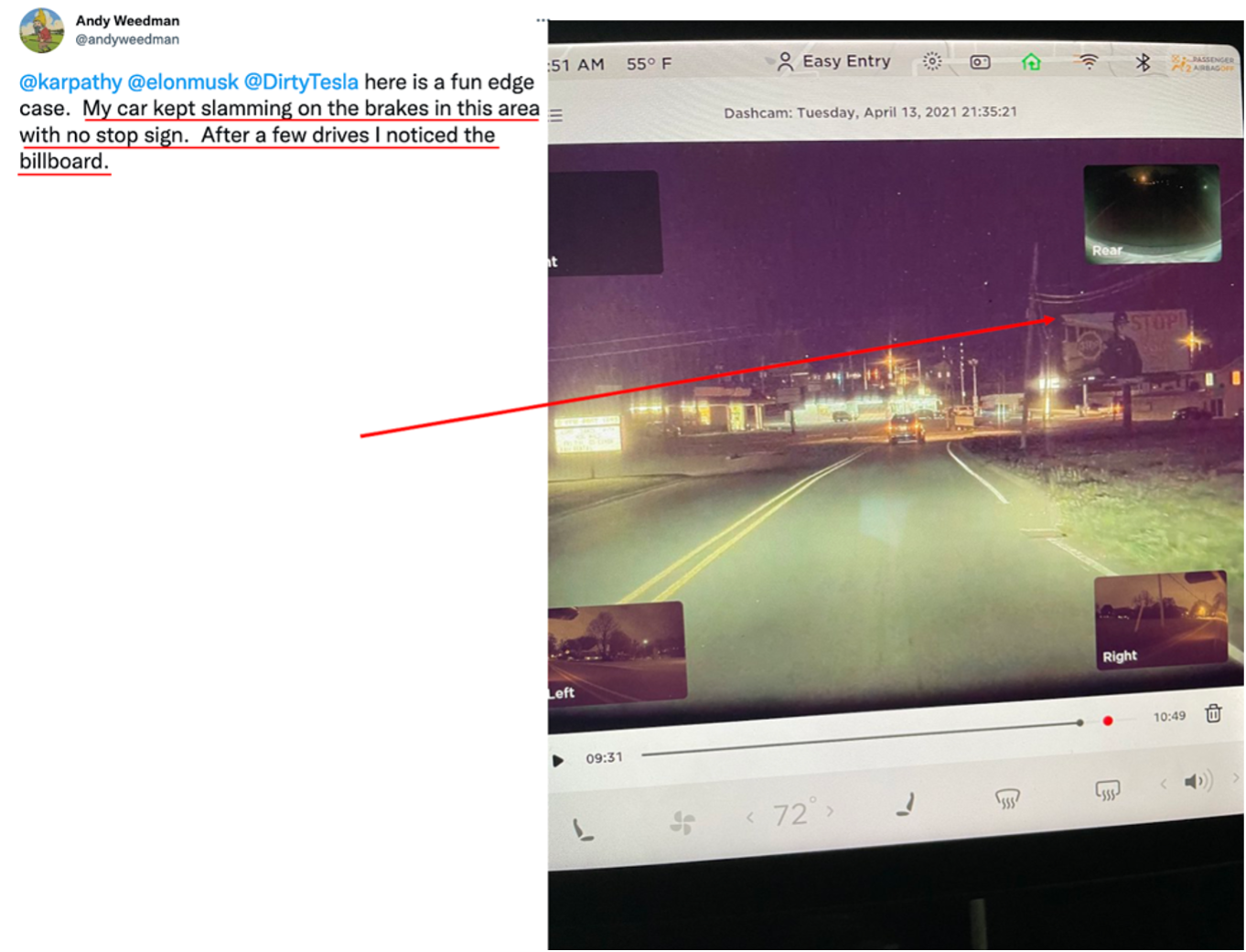
Dr. Mitchell then turned our focus to Moravec’s paradox, which she had alluded to earlier in her presentation. Moravec’s paradox states, “It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility” (Moravec, Hans. Mind Children). So how can we correct for AI’s lack of perception and common sense? Dr. Mitchell then discussed a domain that has been proposed to evaluate humans and machines based on the “core knowledge” systems that have been identified in both humans and in some animal species. The idea of innate “core knowledge” has been proposed by Elizabeth Spelke, a cognitive psychologist and director of the Laboratory for Developmental Studies at Harvard University. Dr. Spelke’s work involves identifying the sources of uniquely human cognitive capacities and how those abilities develop from birth through adulthood.
Without being able to measure and compare human intelligence to machine intelligence, we cannot hope to provide machines the feedback necessary to improve their performance. Dr. Mitchell hopes that by creating methods to measure and compare performance of both humans and AI, we will be able to get past the hurdle of artificial intelligence simultaneously being both our smartest and dumbest companion.
Lastly, Dr. David Danks turned our attention away from artificial intelligence itself, and instead towards the framing of the discussion surrounding how AI research is conducted and funded. In his presentation, titled “Letting a Thousand AI’s Bloom”, Dr. Danks discussed two prevailing visions of the nature of scientific efforts. The first ideology is exemplified by Thomas Kuhn. Kuhn believed that the sciences are controlled by the dominant paradigms of the time, meaning most scientists are gripped by the same view or way of thinking, such as the widely held belief that the big bang theory created the universe. This Kuhnian way of thought can lead to homogenous thinking, said Danks, as fewer scientists think outside of the box and challenge the predominantly held norms of the day.
Philosopher Paul Feyerabend offered a contrasting ideology. He believed that scientists should approach problems from divergent points of view. To this end, Feyerabend argued that we should “let one thousand flowers bloom”. In his view, scientists should be researching ouija boards and the theory of astrology, because you can never be sure that the currently held paradigm is correct and science cannot be advanced without questioning even the most staunchly held paradigms. This philosophy leads to more heterogeneous thinking as more outlandish theories are proposed and researched under this vision for scientific progress.
Dr. Danks says that we can look at the scientific visions of Kuhn and Feyerabend as two ends of an extreme. He explained that completely homogenous thinking would hinder scientific inquiry, but letting every flower of an idea bloom is also excessive, and so we can eliminate some areas of research, such as studying ouija boards and astrology. Dr. Danks further opined that it can be useful to think about the benefits and drawbacks of having more heterogeneous and homogeneous modes of thought. The more homogeneous our thought is, the more rapid short term progress we can make on recognized fields and theories that are widely held as important. On the other hand, a more heterogeneous shared vision of science would produce more novel theories and ideas that may not otherwise be developed. This comes at the cost of wasting more resources on theories that don’t pan out and dedicating less time and fewer resources to the fields of study which most benefit society.
Dr. Danks’ pointed out that, practically, it is much easier to allocate funding for research in a homogeneous community, as everyone shares a similar perspective. That paradigm can also be turned towards research opportunities that are most valuable to society, thereby increasing public interest and also funding.
Danks proposed that it matters where we fall on this continuum in terms of our vision for how we conduct scientific research. Falling too far towards either end of the extreme can seriously hinder progress, and unfortunately, Dr, Danks said, we are beginning to fall on one extreme in AI research.
In the graph below, Danks directed our attention to the data from 2014 to the present.
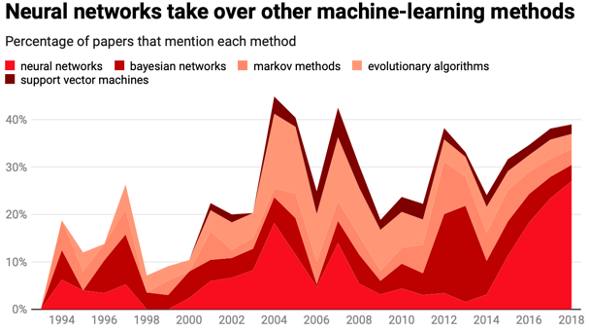
MIT Technology Review
As we can see, the percentage of papers which mention neural networks increases by nearly sevenfold in only 4 years. The vast majority of AI research today is focused on deep learning, and studies on neural networks are crowding out other forms of artificial intelligence. Our research on AI is becoming too homogenous, Danks said, and we are neglecting other important and valuable forms of AI. To this end, Danks proposed two solutions.
First, he suggested that we could tackle the homogeneity problem from the supply side by ensuring proper funding for forms of AI beyond deep learning. Those allocating funds would do well to consider the types of AI that are being funded, and perhaps incentivize a diversity of AI applications.
On the other hand, we can also face this problem from the demand side. Much of the funding towards AI focuses on problems that we already know can be solved, but what about those challenges that we heard about earlier from Dr. Mitchell? For example, where is the funding for incorporating common sense into AI systems? We should not accept AI as it is now, says Dr. Danks, and we need to strive to make it better. To that end, he proposes that we focus first on improving the technology that underlies neural networks before funding more applications of the networks themselves.
Stay tuned for the Q&A from the panel, which will be released on the CCC blog tomorrow.





