
CCC supported three scientific sessions at this year’s AAAS Annual Conference, and in case you weren’t able to attend in person, we will be recapping each session. This week, we will summarize the highlights of the session, “Generative AI in Science: Promises and Pitfalls.” In Part Three, we summarize the presentation by Dr. Duncan Watson-Parris, assistant professor at Scripps Institution of Oceanography and the Halıcıoğlu Data Science Institute at UC San Diego.
Following Dr. Markus Buehler’s presentation on generative AI in mechanobiology, Dr. Watson-Parris turned the audience’s attention to generative AI applications in the climate sciences. He began by outlining the difference between climate and weather. Weather refers to short term atmospheric conditions, whereas climate describes long term atmospheric conditions. In short, climate is what you expect, weather is what you get. “One of the largest issues with climate modeling,” says Watson-Parris, “is that we only have recent data from when we began taking climate measurements.” Creating accurate models that predict future climate patterns and weather events is especially difficult, because we can’t verify the results in the real world until these events come to pass. However, for shorter term predictions, such as weather forecasts over the next three days, we can easily verify the accuracy of these models.
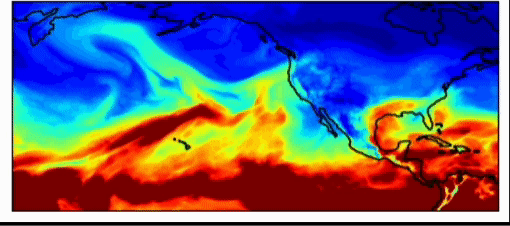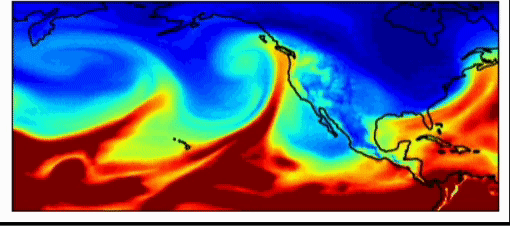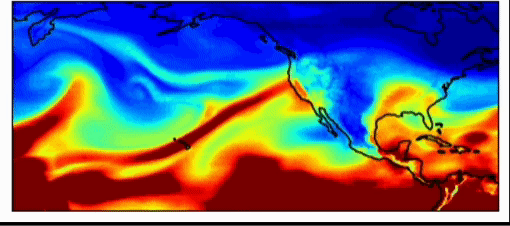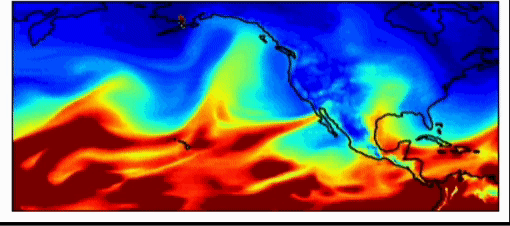
Industry weather models are very accurate already. These models perform with just as much accuracy as the national weather forecasting models for short term estimations (~3-7 day forecasts). However, one of the largest issues with weather forecasting is sampling initial weather conditions. As Dr. Willett pointed out in her talk, very slightly different starting conditions may yield vastly different results. This is true in weather simulations, says Dr. Watson-Parris, which can have important real-world impacts. The weather pattern, shown below, introduced an atmospheric river in 2017 in the California and Oregon region which generated so much rain that the Oroville dam burst, causing millions of dollars in damage. This event was difficult to forecast, because it was an extreme event, an outlier. Machine learning forecasts allow us to do much larger amounts of sampling to predict more extreme weather events, allowing us to better prepare for them.
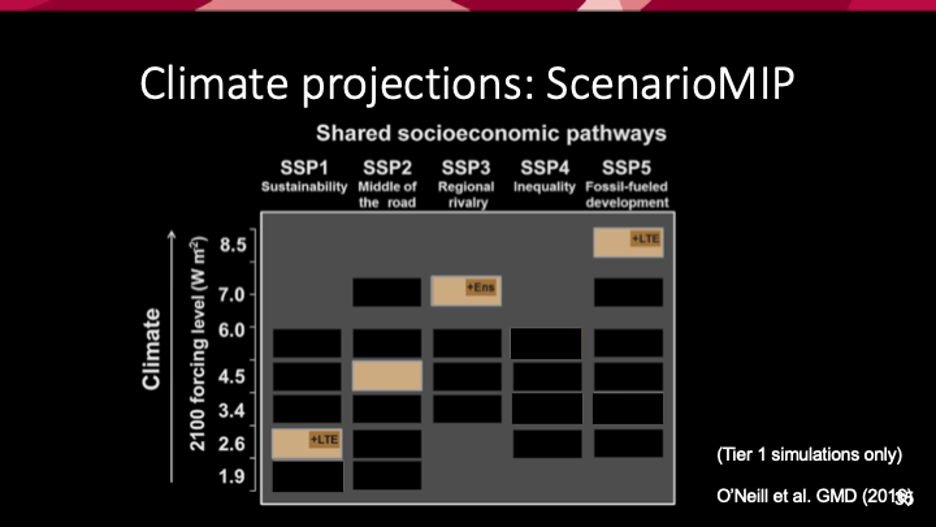
When researchers think about the climate system, explains Dr. Watson-Parris, looking over larger scales and over larger periods of time, eventually they see how average clouds look over seasons and they can look at statistics of systems. These statistics are governed by the boundary conditions of the Earth system – the amount of energy coming in and going out. When the problem is framed in this way, we can then predict on average where clouds will be during the seasons, and there are opportunities for using machine learning to improve and explore these different predictions. One of the tasks of climate models is to make projections – to understand how the climate will change in the future under different human influences. These are designed to explore possible futures. To do this, researchers generate more plausible socioeconomic pathways for how society might act in the future.
Below is an image Dr. Watson-Parris displayed, which depicts some possible pathways society may go down in the future that need to be taken into account in these climate models. On the left hand side, is a sustainability model which by the end of the century keeps climate forcing – the amount of warming humans impose on the system – to a lower level. On the other hand, the fossil fuel development scenario on the right hand side is a kind of worst case scenario. This is a very sparse sampling of ways humanity may get to 2100.
In practice, when deciding the climate scenario and communicating with policymakers who want to understand the impact of their decisions, researchers train simple climate model emulators. These emulators take into account projections for different emissions, such as CO2 and methane, and short-lived climate forces like black carbon and sulfate, and researchers can emulate the response of these climate models, based on training data. “We can fit more or less complex models of the global response of the global mean temperature to these emissions”, says Watson-Parris. “These models work reasonably well because scientists have a good understanding of the underlying physics. But no one lives in the global mean temperature, and we will feel all of these changes differently, so to understand regional changes, scientists take the global mean and scale the pattern change to regional situations. These models work well, but they lose the impact that these emissions might have locally. For example, black carbon, in particular, is emitted largely in South Asia, and the impacts of that will be felt mostly in South Asia.”
If this problem is framed in a regression setting, we see there may be opportunities for machine learning. “As part of the Climate Bench paper we wrote a year ago,” says Dr. Watson-Parris, “we said we can take the emissions and concentrations of greenhouse gasses and maps of emissions of sulfate and black carbon and regress those directly onto the climate models to see predictions. We also don’t have to constrain ourselves to temperature, we can take into account precipitation and other variables. This way we can build emulators of the climate models that predict what the climate model will produce for a given amount of CO2 emitted and allow us to run these models on a laptop rather than a supercomputer.”
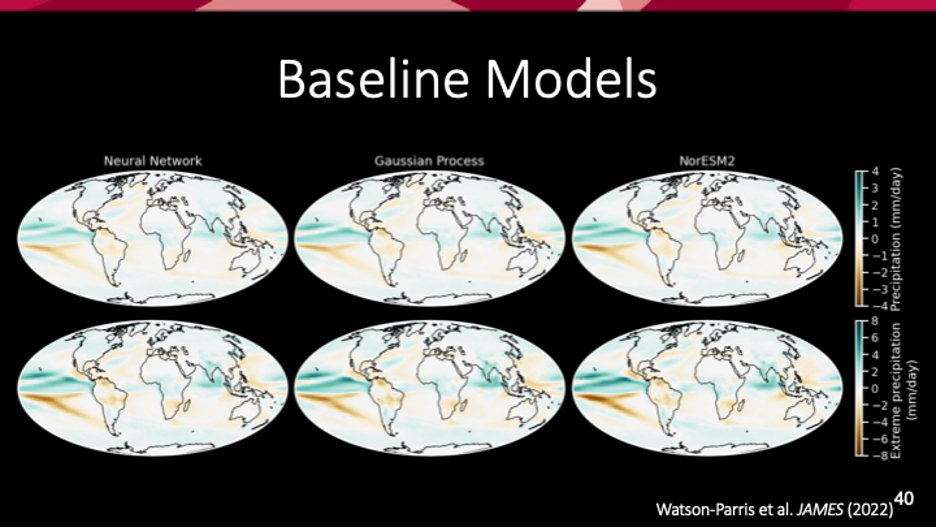
Dr. Watson-Parris then displayed an image of 3 different realizations of global temperature response in a held-back, middle of the road climate policy scenario. The first two columns are machine learning emulators, and the third is a full complexity climate model simulation which took a week on a supercomputer. “The results from each of these models are almost indistinguishable,” says Watson-Parris. These climate models do a very good job of accurately predicting this pattern of warming. They even do a good job of predicting precipitation patterns. These models improve accessibility and participation, and allow smaller organizations and policymakers to participate in climate prediction and exploration without needing huge amounts of funding or infrastructure.
These models are not generative AI, they are straight regression models, and a given input will always return the same result. However, opportunities to use generative and diffusion models to take the probabilistic distributions of weather to generate weather states are being explored today. Researchers are using these models to predict the climate and weather patterns of the future, given different climate forcing scenarios. “Difficulties remain”, says Dr. Watson-Parris, “because there is still no ‘ground truth’ to verify predictions, and we still need to figure out how to calibrate statistical models, but this is the future of climate prediction, and I am optimistic that these tools will increase accessibility, participation, and understanding of the future of climate science.”
Thank you for reading! Click here to read the final post of this four-part blog series, which summarizes the Q&A portion of this panel.






