

CCC supported three scientific sessions at this year’s AAAS Annual Conference, and in case you weren’t able to attend in person, we are recapping each session. This week, we are summarizing the highlights of the session, “How Big Trends in Computing are Shaping Science.” In Part 2, we hear from Gabriel Manso, a first year PhD student at Massachusetts Institute of Technology, who explains the computational limits of deep learning.
Gabriel Manso, a first-year PhD student at MIT and a member of the MIT FutureTech research group, discussed the computational limits of deep learning along with insights from his research. Deep learning is pervasive across most areas of science today, however it has very specific constraints. Mr. Manso first gave an example of deep learning in image classification, specifically using the ImageNet dataset. The graph below displays the increase in performance of systems trying to recognize entities within images in the ImageNet dataset since 2012. Each of the dots in the graph represents the best model for each year, and the performance of the models increased rapidly between 2012 and 2020. “If we continued along this trend”, said Manso, “we should roughly expect to achieve an error rate of 5% in 2026 and 3% in 2029.”
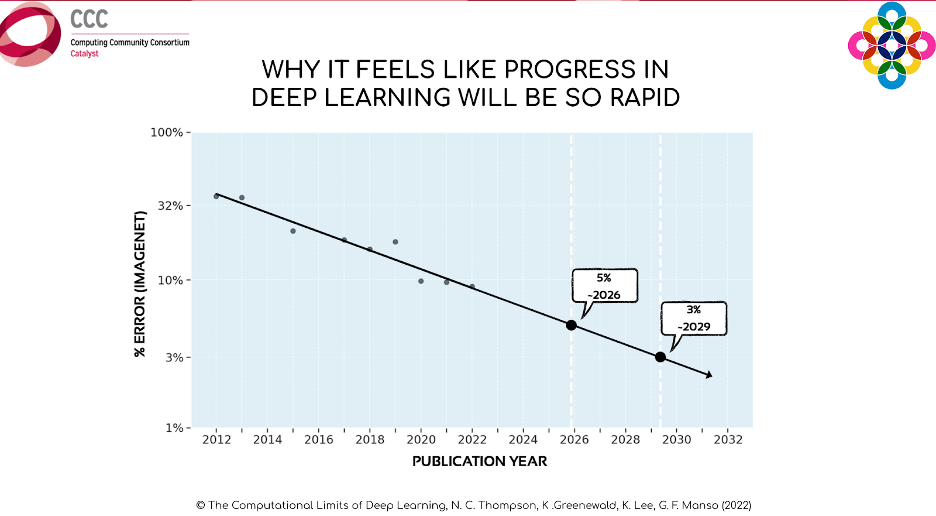
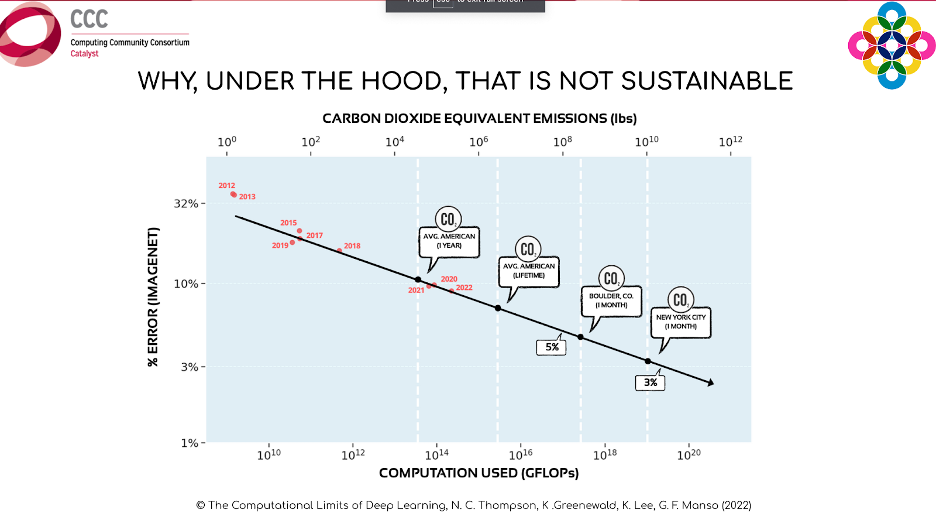
However, this chart does not take into account the massive increases in computing power that each model required to achieve such progress. The graph below shows the same models and their error rates, but instead of representing their progress over time, the X-axis displays the increased compute requirements of each of these models. “To actually achieve an error rate of 5% or 3%, we are not limited simply by the time it takes to develop new models, but by the ability to build more powerful computers to train new models.”

“Another factor to consider”, said Manso, “are the increasing environmental costs (CO2 emissions) associated with training these more computationally intensive models. Training one model to have a 3% error rate on the ImageNet dataset, according to estimates from 2022, would possibly lead us to produce about the same amount of CO2 as the entirety of New York City produces in a month. And that is just one model. Imagine the amount of CO2 that would be generated if all of the large tech companies were training models that are this computationally costly.” Manso reiterates what he said by concluding, “It’s important to note that this prediction line takes into account that we won’t do anything to prevent this from happening, and of course, we have been trying to do many, many things to avoid this catastrophic situation; however, it is important to note that over time we have been both dramatically increased the amount of computing power being used and the amount of carbon dioxide being produced by this models, and people should be aware of that.”
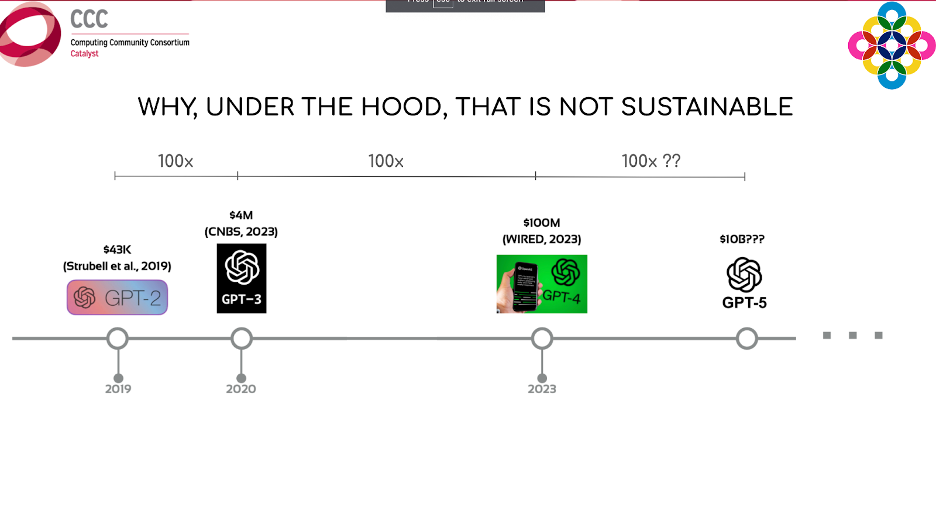
These models are also extremely costly in terms of financial investment. However, according to recent studies, training costs make up only about 10% of the costs associated with these models. The other 90% comes from deployment and inference costs. The figure below shows the rapid increase in costs to train more and more advanced versions of ChatGPT. It only cost $40,000 five years ago to train a top of the line generative model, but that price is quickly ballooning into tens of billions of dollars. “Because training these models is so capital intensive” said Manso, “we are quickly moving to a future where very few models will be competitive, and enormous amounts of power will be held by just a handful of massive tech companies.”
This final graph below, shows the amount of computing power needed to train the most relevant machine learning models across different science domains over time. Up until 2010, the amount of computing power doubled at a rate of about 21 months, roughly following Moore’s Law. In 2010, however, people realized they could use GPUs to train these models, and the doubling rate dropped down to only every 6 months.
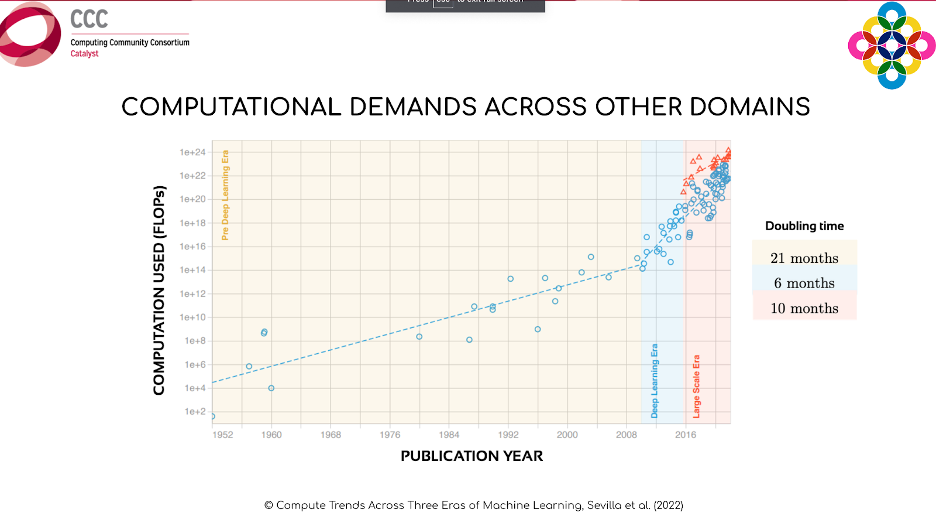
“Because Moore’s Law has broken down, to continue to achieve large gains in computing power, we will need to invest heavily in AI hardware accelerators like GPUs and TPUs,” said Manso. “We will also need to focus on improvements in algorithm efficiency, which can be just as important as advances in hardware.”
Thank you so much for reading! Tomorrow, we will recap Dr. Jayson Lynch’s presentation, which will address how fast algorithms are improving.





